一直以来我都没能完全理解操作系统是如何处理 I/O 这些操作的,这些操作也是容易浪费资源以及 WPF 等桌面应用程序响应不及时的根源之一。今天早上,读到了《CLR via C#》中关于这一主题的章节,让我茅塞顿开。
假设有一台装了 Windows 的 PC,有一个硬盘连接着系统。
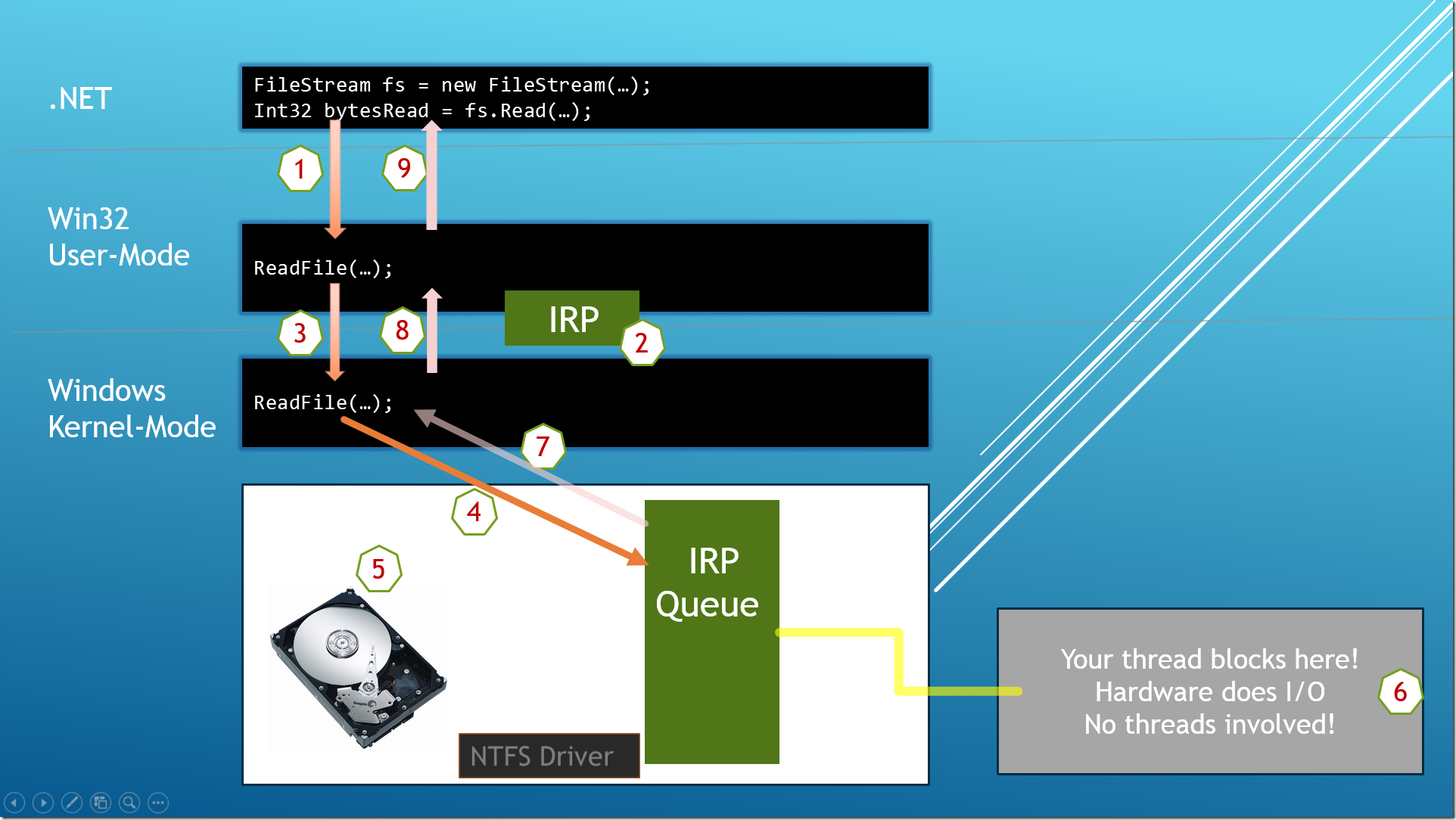
上图是 Microsoft Windows 处理同步 I/O 的流程,下面做一些简单的解释:
在我们的应用程序中,试图打开一个硬盘上的文件,并且读取以返回它的字节流。程序发出读取文件的请求,最后将返回的字节流存储在一个变量中。
步骤1:当程序调用 FileStream 的 Read 方法时,线程从托管代码切换到用户模式原生代码,Read 方法在内部调用 Win32 的 ReadFile 函数。
步骤2:ReadFile 函数收集一个小型的数据结构 IRP,这个 IRP 中包含了这个文件的句柄、文件流起始位置在文件内部的偏移量、文件流数组的地址、文件流的长度以及其他的一些信息。
步骤3:ReadFile 函数被 Windows 内核执行,这个时候线程从用户模式原生代码(native/user-mode code)转换为内核模式原生代码(native/kernel-mode code),同时将 IRP 数据结构传递给内核。
步骤4:从上面传来的 IRP 结构中,Windows 内核读取设备的句柄,便知道这个 I/O 操作需要什么设备,然后内核将 IRP 传递给对应设备的 IRP 队列。每一个设备维护自己的 IRP 队列,这个队列中包含了计算机中各个处理器发来的请求。
步骤5:当有 IRP 包出现在队列中的时候,设备驱动就会把这些IRP信息传递给真实硬件(此处即是硬盘)的电路板。
步骤6:当硬件在处理 I/O 请求的时候,对应的线程就没有事情可以做了,所以Windows就将线程设置为 sleep 状态以避免浪费 CPU 资源(CPU time),但是这却依然不能避免浪费了其他资源,比如内存空间,诸如用户模式栈(user-mode stack)、内核模式栈(kernel-mode stack)、线程环境块(TEB: thread environment block)以及其他的一些数据结构。这些资源并没有被使用,但是却留在了内存中。另外,如果应用程序是 GUI 相关的(WPF, Windows Store app等等)就会造成假死的无响应状态。
步骤7, 8 , 9:最后硬件设备完成 I/O 的工作,Windows 就会激活线程,分派给 CPU,让它沿路返回到托管线程中。
相信你也看出同步I/O的瓶颈在哪里了,硬件真正在处理I/O请求的那段时期,线程就被block住了。假设有多个请求到来,线程池这个时候就会创建另一个线程将信息传送给 IRP 队列,新来的线程同样进入 sleep 状态,等待设备处理,这样消耗的资源越积越多却几乎得不到使用。
最糟糕的是,当设备处理完了这些请求,在 CPU 内核不够多的情况下,线程中最耗时的上下文切换将会严重拖累整个系统。
解决这一困境的最有利方法便是尽量让 Windows 异步的处理 I/O 请求。
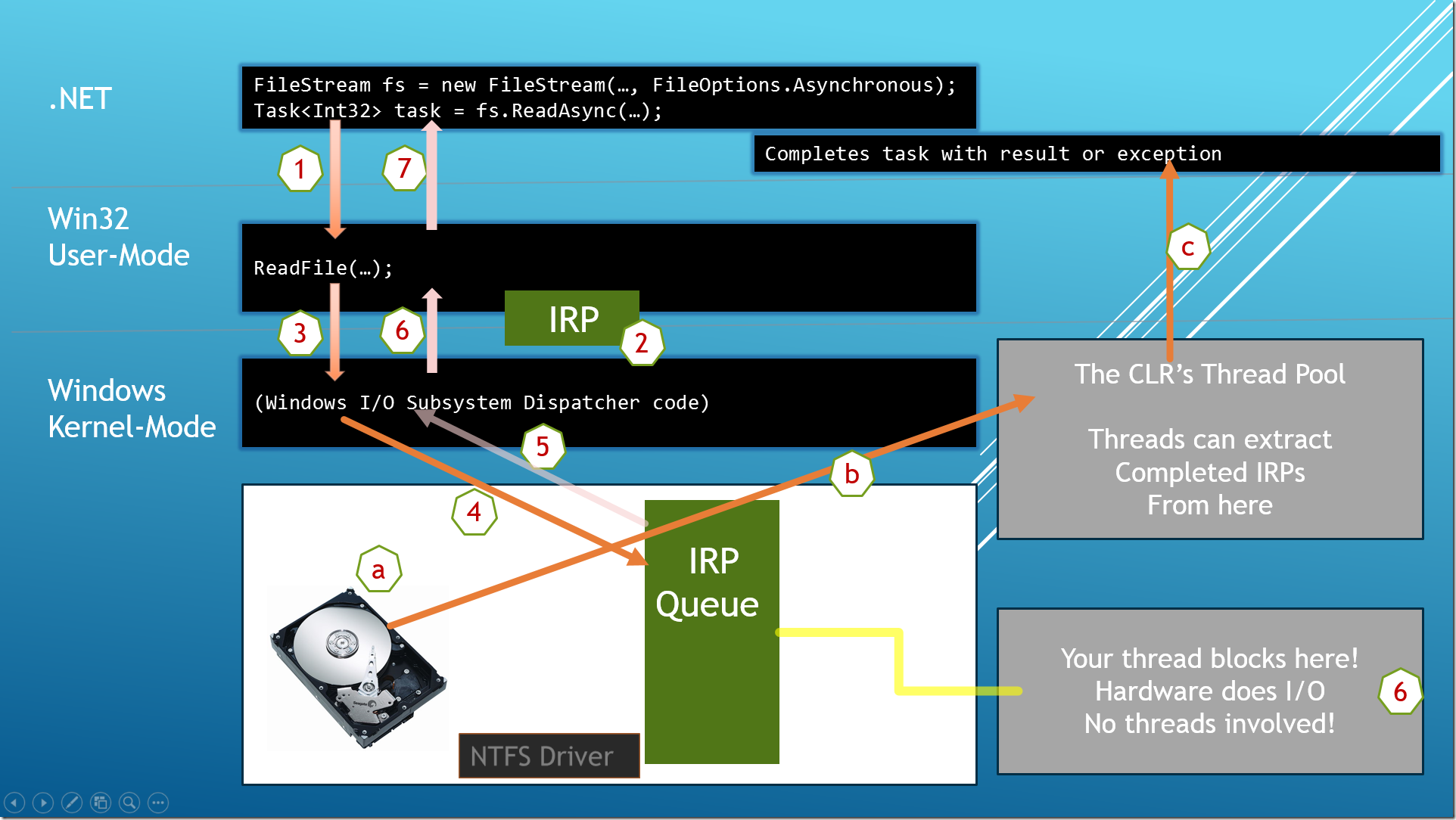
与同步的代码类似,从硬盘中打开一个文件,并且返回它的字节流。只是不同的是这次传递了 FileOptions.Asynchronous 标志位,以告诉 Windows 将读写操作都异步来执行。
步骤1:调用 FileStream 的 ReadAsync 方法来读取文件数据,ReadAsync 方法在内部调用 Win32 的 ReadFile 函数。
步骤2:ReadFile函数收集IRP信息,就像在同步的那部分一样。
步骤3:将 IRP 信息传递给 Windows 内核。
步骤4:Windows 将 IRP 添加到硬盘的 IRP 队列中。
步骤5, 6, 7:不同于同步操作中的流程,这个时候线程并没有被 block 住,线程立刻沿原路返回到了 ReadAsync 方法中。
这个时候,很明显 IRP 并没有被真实的硬件所处理,所以返回的数据其实并不是读取到的文件字节流,返回类型为一个 Task 对象。通过这个对象,你可以调用 ContinueWith 方法来注册一个回调函数来处理 I/O 真正被执行完后的数据,亦即读取到的文件内容,或者是中途出现的异常等等。或者你可以使用 C# 5.0 的一些 async/await 语法,通过这些语法你就可以像写同步代码那样来写异步方法。
步骤a → b → c:当硬件真正的完成了 IRP 的处理(a)后,它将会把完成的 IRP 放到 CLR 线程池中(b)。未来的某个时刻,线程池将会释放完成的 IRP 信息并且执行相应的代码来完成 task,返回结果或者抛出一个异常信息等等。这个步骤结束后,你便可以使用真正的 I/O 结果了。
通过这种方式,当再有多个请求到来时,线程池不会创建多个线程来处理这些请求,相反的它只会维护一个线程。系统资源的利用率得到大幅提升,垃圾回收也会变得非常快(得益于更少的线程存在于进程中),最终上下文切换的问题也不复存在了。当然,你若使用多核的机器,线程池自然也会创建多个线程来处理大量的请求,但依然没有上下文切换的问题,这一切线程池都会做到最大程度的优化。
所以,当我们有 10 个同类型(比如都需要读取文件内容)的 I/O 请求到来时,假设每一个请求耗时 5s,用同步的方式来执行就会花去 50s 的时间,用异步的方式则只会花去 5s 的时间,异步执行的时间遵循木桶原理,它等于耗时最多的操作所需要的时间。
如果你的应用程序是 GUI 类型的,那么用异步 I/O 无疑是最用户友好的。事实上 Silverlight 和 Windows Store app 必须使用异步 I/O,这是框架所约束的,因为平时所使用的同步 API 它们均不提供。这帮助开发者养成良好的习惯,避免将 GUI 线程 block 住使得用户界面失去响应。